멀티프로세서 스케줄링의 기본을 알아보자. 나중에 병행성(concurrency)에 대해 공부하고 다시 복습하면 좋을 것이다.
최근에는 여러개의 코어가 하나의 칩에 내장된 멀티코어 프로세서가 대중화 되었다. 하지만 전통적인 프로그램들은 오직 하나의 CPU만 사용하도록 설계되었다. 이 문제를 해결하려면 응용 프로그램을 병렬(parallel) 로 실행되도록 다시 작성해야 한다.
동시성(Concurrency) vs 병렬성(Parallelism) 참고

보통 쓰레드를 여러 코어에 할당하는 방식을 통해 이를 해결한다.
운영체제도 이에 대응해야 한다. 우리가 지금까지 배운 CPU 스케줄링 기법은 단일 CPU환경에서 논의된 내용이다. 이를 멀티코어 환경에서 동작하도록 확장해보자. 핵심 질문 : 여러 CPU에 작업을 어떻게 스케줄 해야 하는가
1. 배경: 멀티프로세서 구조
단일 CPU 하드웨어와 멀티 CPU 하드웨어가 어떻게 다른가? 다수의 프로세서간 데이터 공유, 그리고 하드웨어 캐시의 사용 방식에서 근본적인 차이가 발생한다. 구체적인 내용을 살펴보긴 어려우니, 개념적으로만 다뤄보자.
단일 CPU 시스템에는 하드웨어 캐시 계층이 존재한다. 캐시는 메인 메모리에서 자주 사용되는 데이터의 복사본을 저장하는 작고 빠른 메모리이다. 캐시는 크기가 작은 대신 메인 메모리보다 훨씬 빠르게 데이터를 가져올 수 있다.
프로세서가 데이터가 다시 사용될 것으로 예상하면 읽은 데이터의 복사본은 캐시 메모리에 저장하고, 나중에 데이터를 읽을 때 캐시에 해당 데이터가 존재하는지 검사한다.
캐시는 지역성(locality)에 기반한다.
- 시간 지역성(temporal locality): 데이터가 한 번 접근되면 가까운 미래에 다시 접근될 확률이 높다. ex) 루프에서 여러 번 반복해서 접근되는 변수
- 공간 지역성(spatial locality): 프로그램이 주소 x의 데이터를 접근하면, x 근처에 있는 데이터가 접근될 확률이 높다. ex) 전체 배열을 차례대로 접근하는 프로그램
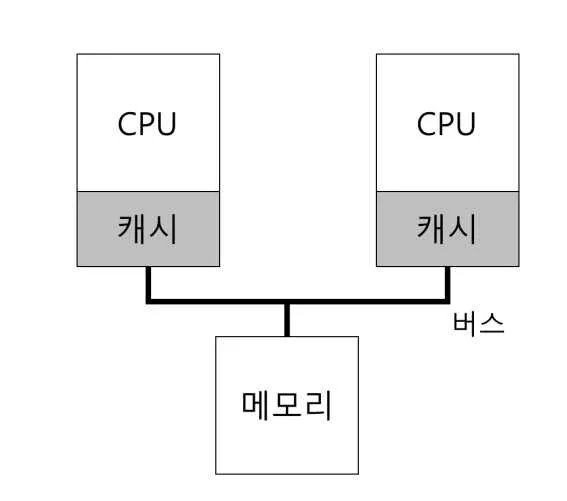
그런데 이렇게 하나의 시스템에 여러 CPU가 존재하고, 하나의 공유 메모리가 존재하는 경우에는 어떤 일이 일어날까?
CPU 1에서 실행 중인 프로그램이 주소 A에 써있는 값 D를 읽는다고 가정해보자. 메인 메모리로부터 값 D를 읽고 값을 D’으로 변경한다. 이 때 메인 메모리에 데이터를 쓰는 것은 오래 걸리기 때문에 보통 캐시에 D’ 값을 쓰고 메인 메모리에는 나중에 반영한다. 이 때 CPU 2에서 주소 A의 값을 읽으면 D’가 아닌 D를 읽게 된다.
이를 캐시 일관성 문제 (cache coherence) 라고 한다. 캐시 일관성 문제는 어떻게 해결할까? 하드웨어가 메모리 주소를 계속 감시하고, 관리하는 해결책이 있다. 여러 개의 프로세스들이 하나의 메모리에 갱신할 때 공유되도록, 버스 기반 시스템에서 버스 스누핑 이라는 기법을 사용한다.
버스 스누핑
캐시가 자신과 연결된 메모리를 연결하는 버스의 통신 상황을 모니터링하다, 캐시 데이터에 대한 변경이 발생하면 자신의 복사본을 무효화 시키거나 새로운 값을 캐시에 기록한다.
2. 동기화
캐시가 일관성 유지를 담당한다면, 운영체제는 공유 데이터에 접근할 때 어떻게 해야할까?
CPU가 동일한 데이터 또는 구조체에 접근할 때, 올바른 연산 결과를 보장하기 위해 락과 같은 상호 배제를 보장하는 동기화 기법이 사용된다.
연결 리스트에서 원소를 삭제하는 코드를 생각해보자.
 사용자가 함수를 두 번 호출하여 두 쓰레드가 동시에 루틴으로 진입했을 때, 포인터에는 같은 메모리 주소가 기록되고, 같은 메모리를 두 번 해제하게 된다. 두 번 호출했는데, 한 번만 지워졌다.
사용자가 함수를 두 번 호출하여 두 쓰레드가 동시에 루틴으로 진입했을 때, 포인터에는 같은 메모리 주소가 기록되고, 같은 메모리를 두 번 해제하게 된다. 두 번 호출했는데, 한 번만 지워졌다.
해결책은 락을 걸어서 올바르게 작동하도록 만드는 것이다. 간단한 mutex를 할당하고 (pthread_mutex_t m;) 루틴의 시작에 lock(&m), 마지막에 unlock(&m) 을 추가하면 문제를 해결할 수 있다. 하지만 CPU의 개수가 증가할수록, 동기화된 자료구조에 접근하는 연산은 매우 느려진다.
3. 캐시 친화성
CPU에서 프로세스가 실행될 때, 해당 CPU 캐시와 TLB에 상당한 양의 정보를 올려 놓는데, 이 때문에 다음 번에 실행 될 때 동일한 CPU에서 실행되는 것이 유리하다. 해당 CPU 캐시에 일부 정보가 남아있기 때문이다. 캐시 일관성 프로토콜 때문에 다른 CPU에서 실행되더라도 제대로 실행은 되겠지만, 다른 CPU에서 실행되는 경우 필요한 정보를 캐시에 다시 탑재해야 한다.
CPU 캐시(CPU Cache) 는 CPU와 주기억장치 사이에 위치하여, CPU가 필요로 하는 데이터를 미리 저장해 놓는 고속 메모리이다. CPU가 데이터를 필요로 할 때, 먼저 CPU 캐시에서 해당 데이터를 찾는다. 이때 해당 데이터가 CPU 캐시에 있으면 ‘캐시 히트(Cache Hit)‘라고 하며, 없으면 ‘캐시 미스(Cache Miss)‘라고 한다.
반면, TLB(Translation Lookaside Buffer) 는 가상 메모리 시스템에서 가상 주소를 물리 주소로 변환하는 과정을 가속화하기 위해 사용하는 캐시이다. CPU가 데이터를 참조할 때 가상 주소를 물리 주소로 변환해야 하는데, 이때 먼저 TLB를 조회한다. TLB에 해당 정보가 있으면 ‘TLB 히트’라고 하고, 없으면 ‘TLB 미스’라고 한다.
두 기술 모두 CPU의 작업을 가속화하기 위한 캐시 메모리이지만, 저장하는 데이터의 종류와 그 역할에 차이가 있다. CPU 캐시는 실제 데이터를 저장하고, 이 데이터는 CPU가 직접 작업을 수행하는 데 사용된다. 반면에, TLB는 가상 주소와 물리 주소 간의 매핑 정보를 저장하며, 이 정보는 CPU가 메모리에서 데이터를 찾는 데 사용된다. 즉, CPU 캐시는 ‘무엇’을 저장하는 반면, TLB는 ‘어디에’ 정보를 저장하는 역할을 한다.
4. 단일 큐 스케줄링
멀티프로세서 시스템의 스케줄러에 대해 알아보자. 단일 프로세서에서 하던 것 처럼, 그대로 적용할 수 있다. 이러한 방식을 단일 큐 멀티프로세서 스케줄링(single queue multiprocessor scheduling, SQMS) 이라 부른다.
아주 단순하다. CPU가 1개일 때는 작업을 하나씩 선택해서 실행했고, CPU가 2개일 때는 작업을 두개씩 선택해서 실행하면 된다. 하지만 단점이 있다.
- 확장성 (scalability) 결여: 스케줄러가 다수의 CPU에서 동작하도록 코드에 락을 삽입해야 한다. 그래야 실행시킬 다음 작업을 올바르게 찾을 수 있다(동시에 같은 작업 고르면?). CPU 개수가 증가할수록 락은 성능을 크게 저하시킨다.
- 캐시 친화성 (cache affinity): 각 CPU는 공유 큐에서 다음 작업을 선택하기 때문에 각 작업은 CPU를 옮겨다니게 된다.
 특정 작업들에 대해서 캐시 친화성을 고려하여 스케줄링하고, 다른 작업들은 여러군데로 분산시키는 정책을 사용할 수 있긴 하다. 하지만 구현이 복잡해진다.
특정 작업들에 대해서 캐시 친화성을 고려하여 스케줄링하고, 다른 작업들은 여러군데로 분산시키는 정책을 사용할 수 있긴 하다. 하지만 구현이 복잡해진다.
5. 멀티 큐 스케줄링
이러한 문제때문에 일부 시스템은 CPU마다 큐를 하나씩 둔다. 이 방식을 멀티 큐 멀티프로세서 스케줄링(multi-queue multiprocessor scheduling, MQMS)이라고 부른다.
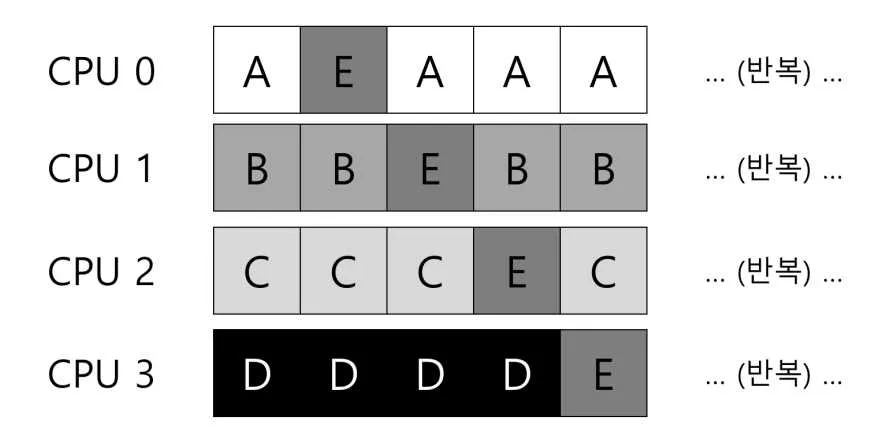
각각의 큐는 라운드 로빈같은 특정 스케줄링 규칙을 따르고 있다. 작업이 여러 스케줄링 큐 중 하나에 배치된다.

에 , 가 배치되었고, 에 , 가 배치되었다.
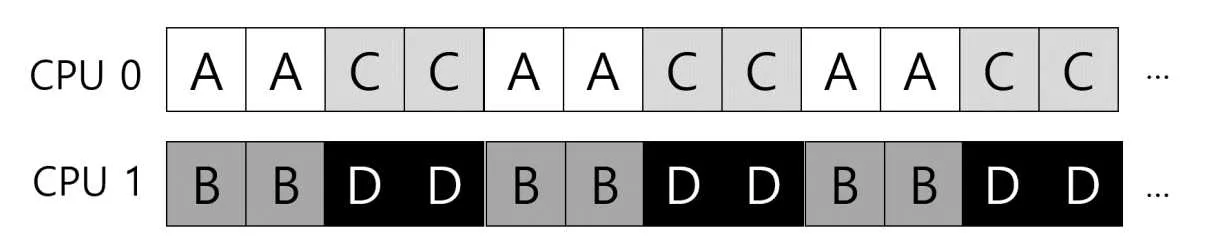
라운드 로빈 방식이라면 이렇게 스케줄링 될 것이다.
SQMS에 비해 확장성이 좋다. CPU 개수가 증가할수록 큐의 개수도 증가하므로 락에 대한 걱정을 할 필요가 없다. 또 MQMS는 캐시 친화적이다. 작업이 같은 CPU에서 계속 실행되기 때문에 캐시에 저장된 내용을 계속 재사용할 수 있다.
하지만 MQMS는 워크로드의 불균형 (load imbalance) 문제를 가지고 있다.
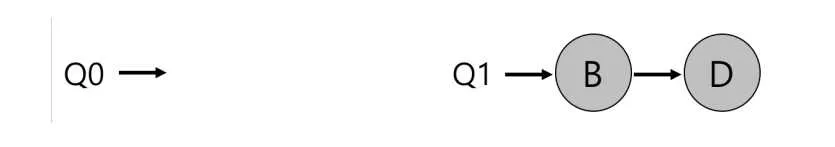
이렇게 에 있는 모든 작업들이 종료된다면

CPU 0은 일을 하지 않을 것이다.
이를 해결하기 위해 작업을 다른 CPU로 이주 (migration) 시킴으로써 워크로드의 균형을 달성할 수 있다.
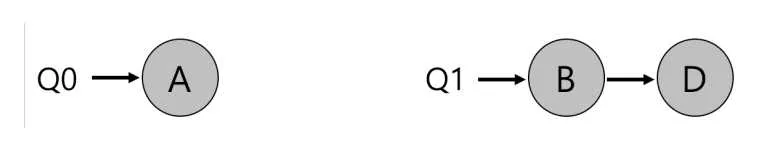
에 작업이 하나, 에 작업이 두 개 있다고 가정하자. 이주 없이 그냥 실행시키면 작업 A가 남들보다 2배의 CPU 자원을 받을 것이다.
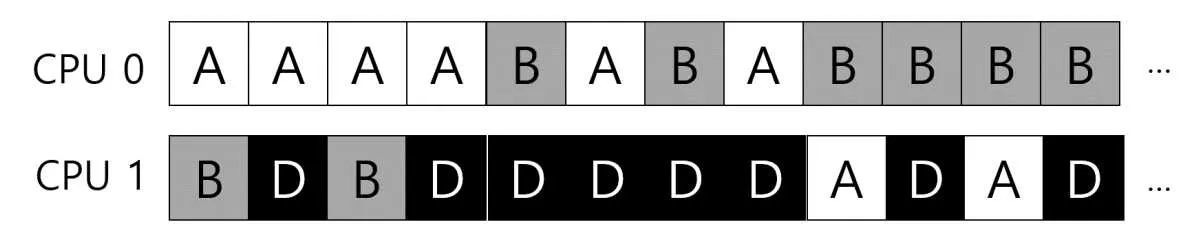
이런 식으로 작업을 지속적으로 이주시켜, 워크로드의 균형을 달성할 수 있다. 모두 8번의 타임 슬라이스를 받았다. 작업이 적게 할당된 큐가, 다른 큐를 가끔 검사한다. 작업이 많다면, 작업을 가져와서 균형을 맞춘다.
6. Linux 멀티프로세서 스케줄러
Linux에는 여러 가지 멀티프로세서 스케줄러가 존재하며, 대표적으로 O(1) 스케줄러, Completely Fair Scheduler(CFS), 그리고 BFS 스케줄러가 있다. 이들 스케줄러는 각기 다른 특성과 장단점을 가지고 있다.
- O(1) 스케줄러: 이는 우선순위 기반 스케줄링 방식으로, 프로세스의 우선순위를 시간에 따라 변경하며 우선순위가 가장 높은 작업을 선택한다. 상호작용을 우선시하는 특징이 있다.
- CFS: 이는 결정론적인 비례배분 방식으로 스케줄링한다. 보폭 스케줄링 방식에 가깝다고 볼 수 있다.
- BFS: 이는 유일하게 단일 큐 방식을 사용하며, 비례배분 방식으로 스케줄링한다. 복잡한 알고리즘인 Earliest Eligible Virtual Deadline First(EEVDF)에 기반을 두고 있다.
7. 요약
멀티프로세서 스케줄링에는 크게 단일 큐 방식과 멀티 큐 방식이 있다.
- 단일 큐 방식: 구현이 간단하고 워크로드의 균형을 잘 맞추는 특징이 있다. 하지만, 많은 프로세서에 대한 확장성과 캐시 친화성이 좋지 않다.
- 멀티 큐 방식: 확장성이 좋고 캐시 친화성을 잘 다루는 반면, 워크로드의 불균형에 취약하고 구현이 복잡하다.
OSTEP 교재 참고