앞에서 배운 반환 시간 혹은 응답 시간을 최적화하는 스케줄러 대신, 각 작업에게 CPU의 일정 비율을 보장하는 것이 목적인 비례 배분 스케줄러에 대해 알아보자.
1. 추첨권 (티켓)
전체 티켓 중 프로세스가 보유한 티켓의 비율이 받아야 할 CPU 자원의 비율이다. 그리고 타임 슬라이스 한 번마다 전체 티켓 중 하나를 무작위로 추첨하여 실행할 프로세스를 결정한다.
0부터 99까지의 티켓 중 A가 0부터 74, B가 75에서 99까지의 티켓을 가지고 있다고 하자.
![]()
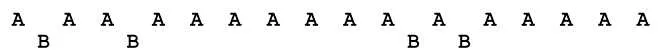 이렇게 뽑힌 티켓 값에 따라 어떤 프로세스를 실행할지 결정한다.
전체 20개의 타임 슬라이스 중, B는 4개(20%) 의 타임 슬라이스를 획득했다. 목표로 했던 25%보다는 적지만, 시간이 지나면 지날수록 25%에 가까워질 것이다.
이렇게 뽑힌 티켓 값에 따라 어떤 프로세스를 실행할지 결정한다.
전체 20개의 타임 슬라이스 중, B는 4개(20%) 의 타임 슬라이스를 획득했다. 목표로 했던 25%보다는 적지만, 시간이 지나면 지날수록 25%에 가까워질 것이다.
2. 추첨 기법
1. 추첨권 화폐(ticket currency)
티켓을 화폐처럼, 환율을 적용해서 스케줄링하는 기법이다. 각각의 사용자가 100장의 global 티켓을 받았다고 가정하자. 사용자 A는 프로세스 A1, A2 두 개를 실행중이고, 자신이 정한 티켓 1000장 중 500장씩 A1, A2에 할당했다. 사용자 B는 프로세스 B에 자신이 정한 티켓 10장 중 10장을 할당했다. 환율을 적용하면, A1은 50장, A2는 50장, B는 100장의 global 티켓을 받는다.
2. 추첨권 양도(ticket transfer)
프로세스가 일시적으로 티켓을 다른 프로세스에게 넘겨줄 수 있다. 예를 들어, 클라이언트 프로세스가 서버에게 특정 작업을 대신해달라고 요청할 때, 티켓을 함께 넘겨주어 작업이 빨리 완료될 수 있도록 한다.
3. 추첨권 팽창(ticket inlation)
프로세스가 일시적으로 자신이 소유한 티켓의 수를 늘이거나 줄일 수 있다. 그런데 이렇게 하면 하나의 욕심 많은 프로세스가 매우 많은 양의 추첨권을 자신에게 할당할 수 있다. 때문에 프로세스간 신뢰 가능한 시스템에서 유용하다. 추첨권 양도처럼 다른 프로세스와 통신할 필요 없이, 혼자 티켓을 늘려 CPU 자원을 많이 받을 수 있다.
3. 구현
난수 발생기, 프로세스들의 집합을 표현하는 자료 구조, 추첨권의 전체 개수 이렇게 3개만 있으면 구현할 수 있다.

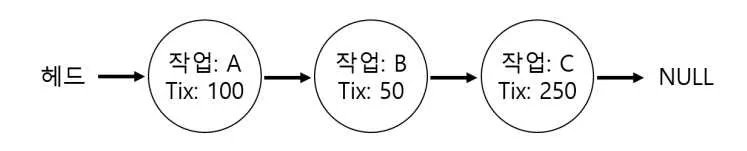
A는 0부터 99, B는 100부터 149, C는 150부터 399까지 티켓을 할당받는다. winner에 난수 300이 할당되었다고 하자. 리스트를 앞에서부터 순회하면서 counter의 값을 증가시킨다. A를 만나면 100, B를 만나면 150이 된다. C를 만나면 400이 되어 난수 300보다 커지므로 당첨자를 찾은 것이다. 리스트를 내림차순으로 정렬 (티켓 많이 받은 프로세스가 앞에 오도록) 하면 좀 더 효율적이다.
4. 예제
같은 개수의 티켓을 보유하고 있고, 동일한 실행 시간을 가지는 프로세스 두 개의 수행 시간을 살펴보자. 두 프로세스를 거의 동시에 종료시키는 것이 목표다.
첫 번째 작업이 종료된 시간을 두 번째 작업이 종료된 시간으로 나눈 지표인 불공정 지표인 를 정의하자. 가 1일 때, 스케줄러는 완벽한 공정 스케줄러이다.
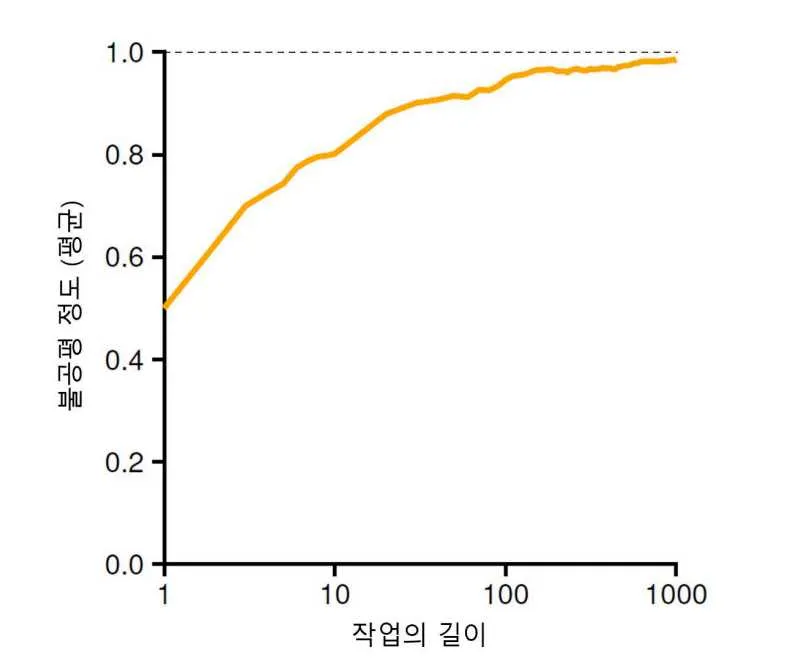
작업의 시간이 짧은 경우, 무작위성에 영향을 많이 받아 불공정 지표가 1에 가깝지 않고, 작업의 시간이 긴 경우 무작위성에 영향을 덜 받아 불공정 지표가 1에 가깝게 나온다.
작업의 길이가 길어야 추첨 스케줄러를 통해 원하는 결과 (공정한 스케줄러) 를 얻을 수 있다.
5. 티켓 배분 방식
티켓을 어떻게 할당하느냐는 문제는 굉장히 어려운 문제이다. 한 가지 접근 방식은 사용자가 어떻게 배분해야 할지 알고 있다고 가정하고, 사용자에게 모두 맡기는 것이다. 사용자에게 티켓을 주고, 실행시키고자 하는 작업들에게 티켓을 배분한다. 하지만 이 방법은 해결책이 될 수 없다.
6. 왜 결정론적 (Deterministic) 방법을 사용하지 않는가
위에서 본 바와 같이, 무작위성을 이용하면 스케줄러를 단순하게 만들 수 있지만 정확한 비율을 보장할 수 없다. 특히 짧은 기간만 실행되는 경우는 더욱 심하다. 때문에 결정론적 공정 배분 스케줄러인 보폭 스케줄링(stride scheduling)을 고안했다.
보폭 스케줄링(Stride Scheduling)
시스템의 각 작업은 ‘보폭’이라는 값을 가지고 있다. 이 보폭은 해당 작업이 가지고 있는 추첨권 수에 반비례하는 값이다. 예를 들어, 작업 A, B, C가 각각 100, 50, 250의 추첨권을 가지고 있다고 가정해보자. 이때 임의의 큰 값을 각 작업의 추첨권 개수로 나누어 보폭을 계산할 수 있다. 여기서는 10,000을 각 작업의 추첨권 개수로 나누면, 각 작업의 보폭은 100, 200 및 40이 된다.
이제 각 작업이 CPU를 사용할 때마다, ‘pass’라는 값이 보폭만큼 증가합니다. 이 ‘pass’ 값은 해당 작업이 얼마나 많이 CPU를 사용했는지를 추적하는 데 사용됩니다. 스케줄러는 이 보폭과 pass 값을 사용하여 어떤 작업을 다음으로 실행시킬지를 결정한다. 가장 작은 pass 값을 가진 작업을 선택하고, 그 작업을 실행한 후에는 해당 작업의 pass 값을 보폭만큼 증가시킨다. 보폭 스케줄링은 각 스케줄링 주기마다 정확한 비율로 CPU를 배분한다.

왜 보폭 스케줄링이 아닌 추첨 스케줄링을 사용하는가?
추첨 스케줄링에는 보폭 스케줄링이 가지고 있지 않은 멋진 특성이 있기 때문. 바로 상태 정보가 필요 없다는 점이다.
보폭 스케줄링에서는 스케줄링 중간에 새로운 작업이 시스템에 도착하면, 그 작업의 pass 값이 얼마가 되어야 할지 결정해야 한다. 그런데 추첨 스케줄링에서는 이러한 정보가 필요 없다. 새로운 작업이 추가될 때, 그냥 새 작업이 가진 추첨권의 개수를 전체 추첨권의 개수에 추가하고 스케줄링을 수행하면 된다. 따라서, 추첨 스케줄링에서는 새로운 작업을 쉽게 추가할 수 있다.
비례 배분 스케줄러는 추첨권 할당량을 비교적 정확하게 결정할 수 있는 환경에서 유용하게 사용된다. 예를 들어, 가상화 데이터 센터에서 Windows 가상 머신에 CPU 사이클의 1/4을 할당하고 나머지는 Linux 시스템에 할당하고 싶은 경우 비례 배분이 간단하고 효과적이다.
OSTEP 교재 참고