이번 장에서는 프로세스를 위한 새로운 개념인 쓰레드 (Thread) 를 소개한다. 프로그램에서 한 순간에 하나의 명령어만을 실행하는 (단일 Program Counter) 고전적인 관점에서 벗어나, 멀티 쓰레드 프로그램은 하나 이상의 실행 지점 (독립적으로 불러들여지고 실행될 수 있는 여러 개의 Program Counter 값) 을 가지고 있다.
각 쓰레드는 프로세스와 유사하지만 쓰레드끼리 주소 공간을 공유하기 때문에 동일한 값에 접근할 수 있다.
하나의 쓰레드의 상태는 프로세스와 유사하게 어디서 명령어들을 불러올지 추적하는 PC와 연산을 위한 레지스터를 가지고 있다. 두 개의 쓰레드가 하나의 프로세서에서 실행 중이라면 두 번째 쓰레드는 문맥 교환을 통해 첫 번째 쓰레드와 교체되어야 한다. 첫 번째 쓰레드가 사용하던 레지스터를 저장하고, 두 번째 쓰레드가 사용하던 레지스터의 내용으로 돌려놓는다는 점에서 프로세스의 문맥 교환과 유사하다.
프로세스가 프로세스 제어 블럭 (PCB) 에 저장하듯, 프로세스의 쓰레드들의 상태를 저장하기 위해 쓰레드 제어 블럭 (TCB) 가 필요하다. 가장 큰 차이점은 쓰레드 간 문맥 교환에서는 주소 공간을 그대로 사용한다는 점이다.
쓰레드와 프로세스의 또 다른 차이는 스택에 있다. 멀티 쓰레드 프로세스의 경우에는, 각 쓰레드가 독립적으로 실행되며, 주소 공간에는 쓰레드마다 스택이 할당되어 있다.
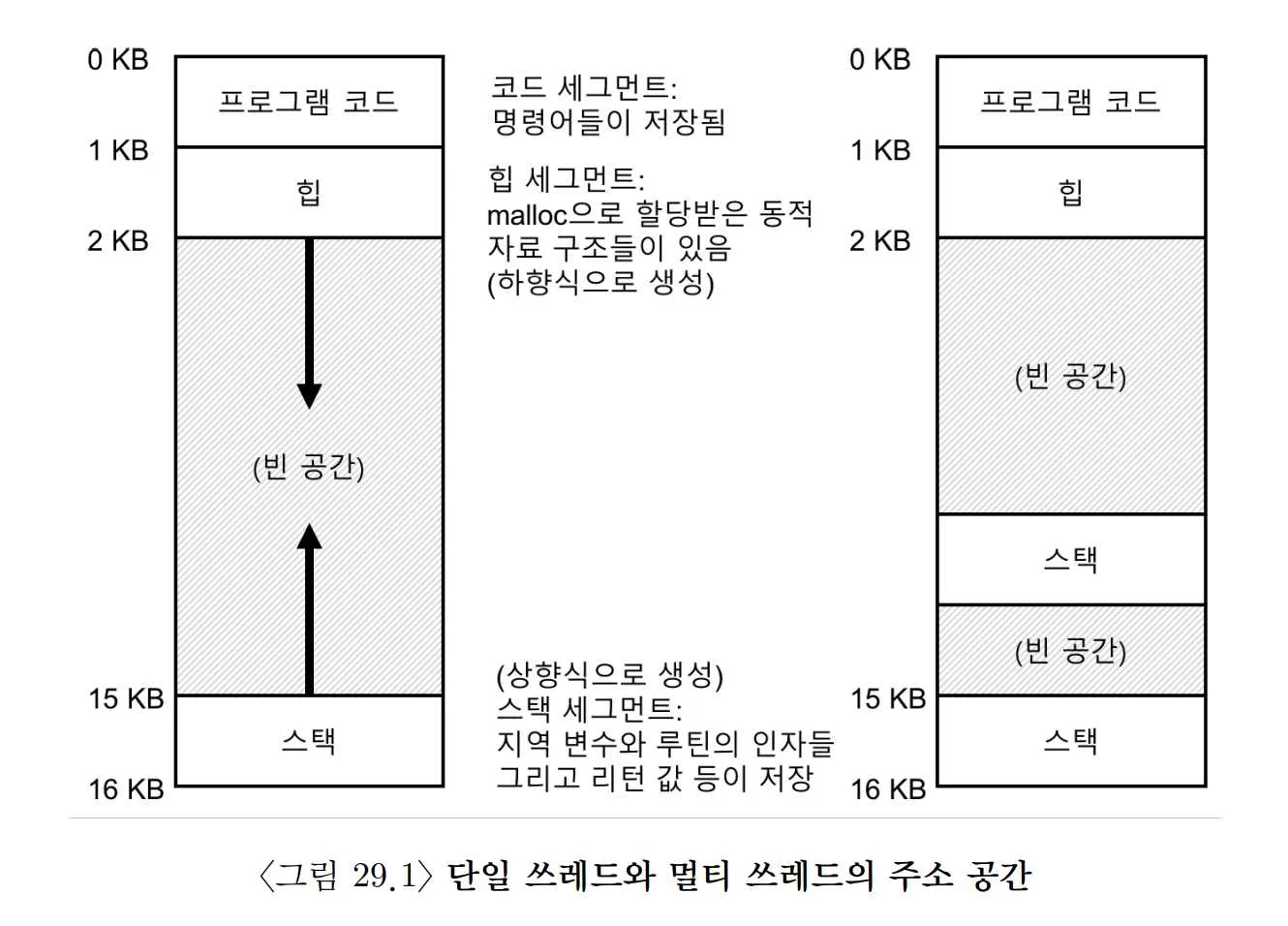
오른쪽 주소 공간에는 두 개의 스택이 존재한다. 스택에서 할당되는 변수들이나 매개변수, 리턴값 등은 해당 쓰레드의 스택인 쓰레드-로컬 저장소(Thread-local storage) 에 저장된다.
쓰레드-로컬 저장소로 인해 정교한 주소 공간의 배치가 무너져버렸다. 스택 사이에 빈 공간이 생겨버렸다. 스택의 크기가 아주 크지 않아도 되기 때문에 대부분의 경우는 문제가 되지 않는다. 재귀 호출을 많이 하면 문제가 생길 수 있다.
예제: 쓰레드 생성
“A”, “B”를 출력하는 독립적인 두 개의 쓰레드를 만들어보자.
#include <stdio.h>
#include <assert.h>
#include <pthread.h>
#include "common.h"
#include "common_threads.h"
void *mythread(void *arg) {
printf("%s\n", (char *) arg);
return NULL;
}
int main(int argc, char *argv[]) {
pthread_t p1, p2;
int rc;
printf("main: begin\n");
pthread_create(&p1, NULL, mythread, "A");
pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main: end\n");
return 0;
}mythread() 함수를 실행할 두 개의 쓰레드를 생성한다. 스케줄러가 어떻게 하느냐에 달려있긴 하지만, 쓰레드가 생성되면 즉시 실행될 수도 있고, 준비 상태에서 실행은 되지 않을 수도 있다.
두 개의 쓰레드를 생성한 후에 메인 쓰레드는 pthread_join()을 호출하여 특정 쓰레드의 동작의 종료를 대기한다.


이렇게 실행 순서는 여러 가지로 나올 수 있다. 쓰레드 1이 쓰레드 2보다 먼저 생성된 경우라도, 스케줄러가 쓰레드 2를 먼저 실행하면 “B”가 “A”보다 먼저 출력될 수도 있다.
쓰레드의 생성이 함수의 호출과 유사하게 보인다. 함수 호출에서는 함수 실행 후에 호출자 (caller) 에게 리턴하는 반면, 쓰레드의 생성에서는 실행할 명령어들을 갖고 있는 새로운 쓰레드가 생성되고, 생성된 쓰레드는 caller와는 별개로 실행된다. 쓰레드 생성 함수가 리턴되기 전에 쓰레드가 실행될 수도 있고, 리턴된 이후에 쓰레드가 실행될 수도 있다.
이렇게 쓰레드는 언제 실행되는지 알기 어렵다.
2. 훨씬 더 어려운 이유: 데이터의 공유
전역 공유 변수를 갱신하는 두 개의 쓰레드에 대한 예제를 살펴보자.
#include <stdio.h>
#include <pthread.h>
#include "ommon.h"
#include "common_threads.h"
static volatile int counter = 0;
// mythread()
// Simply adds 1 to counter repeatedly, in a loop
// No, this is not how you would add 10,000,000 to
// a counter, but it shows the problem nicely.
void *mythread(void *arg) {
printf("%s: begin\n", (char *) arg);
int i;
for (i = 0; i < 1e7; i++) {
counter = counter + 1;
}
printf("%s: done\n", (char *) arg);
return NULL;
}
// main()
//
// Just launches two threads (pthread_create)
// and then waits for them (pthread_join)
int main(int argc, char *argv[]) {
pthread_t p1, p2;
printf("main: begin (counter = %d)\n", counter);
pthread_create(&p1, NULL, mythread, "A");
pthread_create(&p2, NULL, mythread, "B");
// join waits for the threads to finish
pthread_join(p1, NULL);
pthread_join(p2, NULL);
printf("main: done with both (counter = %d)\n", counter);
return 0;
}다음과 같은 결과를 기대할 것이다.
1 prompt> gcc −o main main.c −Wall −pthread
2 prompt> ./main
3 main: begin (counter = 0)
4 A: begin
5 B: begin
6 A: done
7 B: done
8 main: done with both (counter = 20000000)하지만 이 코드를 실행하면 기대한 대로 결과가 출력되지 않는다.
1 prompt> ./main
2 main: begin (counter = 0)
3 A: begin
4 B: begin
5 A: done
6 B: done
7 main: done with both (counter = 19345221)다시 한 번 실행해보면, 또 다른 결과가 나온다.
1 prompt> ./main
2 main: begin (counter = 0)
3 A: begin
4 B: begin
5 A: done
6 B: done
7 main: done with both (counter = 19221041)왜 이런 일이 일어나는 걸까?
3. 제어 없는 스케줄링
왜 이런 일이 일어나는지 알기 위해, 컴파일러가 생성한 코드의 실행 순서를 이해할 필요가 있다.
x86에서 counter를 증가하는 코드의 순서는 다음과 같다.
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1ccounter 변수의 주소가 0x8049a1c이라고 하자. mov 명령어가 명시한 주소의 값을 읽어들인 후, eax 레지스터에 넣는다. 그리고 1을 (0x1) eax 레지스터의 값에 더하는 연산을 한 후, eax 레지스터에 저장된 그 값을 메모리의 원래 주소에 다시 저장한다.
무슨 문제가 생길지 예상할 수 있다.
1번 쓰레드가 counter를 1 증가시키려고 한다. counter에 50이 저장되어 있었기 때문에, eax 레지스터에 넣는다. eax 레지스터에 1을 더해서 eax 레지스터의 값이 51이 된다.
이 때 타이머 인터럽트가 발생하여 운영체제가 1번 쓰레드의 PC와 레지스터 등의 상태를 쓰레드의 TCB에 저장한다.
그리고 2번 쓰레드가 선택되고 counter를 증가시키는 코드 영역에 진입한다. 아직 counter에는 50이 저장되어 있기 때문에 똑같이 50을 읽고, eax 레지스터에 저장하고, 1 증가시키고, 그 값을 counter의 주소 0x8049a1c에 저장한다.
쓰레드는 개별적으로 쓰레드 전용 레지스터를 가지고 있다. 사용 중이던 레지스터들을 저장하고 복구하는 기능 덕분에 이 레지스터들은 가상화되어 각 쓰레드가 개별적으로 사용할 수 있게 된다.
마지막으로 문맥 교환이 한번 더 일어나서 1번 쓰레드가 실행된다. counter의 주소 0x8049a1c에 eax 레지스터의 값 51을 저장한다.

이 예시처럼 명령어의 실행 순서에 따라 결과가 달라지는 상황을 경쟁 조건 (race condition) 이라고 한다. 경쟁 조건에 처한 경우 실행할 때마다 다른 결과를 얻는다. 즉, **비결정적(indeterminate)**이다.
멀티 쓰레드가 같은 코드를 실행할 때 경쟁 조건이 발생하기 때문에 이러한 코드 부분을 임계 영역 (critical section) 이라고 부른다. 공유 변수를 접근하고, 하나 이상의 쓰레드에서 동시에 실행되면 안 되는 코드를 임계 영역이라 부른다.
이 때 필요한 것은 상호 배제 (mutual exclusion) 이다. 이 속성은 하나의 쓰레드가 임계 영역 내의 코드를 실행 중일 때는 다른 쓰레드가 임계 영역에 진입하는 것을 막아 실행할 수 없도록 보장해 준다.
4. 원자성에 대한 바람
강력한 명령어 한 개로 의도한 동작을 수행하여 인터럽트 발생 가능성을 원천 차단할 수 있을까?
memory−add 0x8049a1c, $0x1메모리 상의 위치에 어떤 값을 더하는, 아주 강력한 명령어다. 이 명령어가 원자적으로 실행되는 것을 보장한다고 하자.
“원자적(atomic)“이라는 용어는 여러 개의 작업이나 명령이 있을 때 그 중 하나의 작업 또는 명령이 중간에 인터럽트되거나 중단되지 않고 한 번에 완전히 실행되는 것을 의미합니다. 즉, 원자적인 연산은 “분할 불가능”하다고 볼 수 있습니다. 이는 특히 병렬 처리나 멀티 스레딩 환경에서 중요한 개념입니다. 여러 스레드 또는 프로세스가 동시에 같은 메모리 위치에 접근하는 경우, 원자적 연산은 데이터의 일관성을 유지하기 위해 중요합니다.
어떻게 하면
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c이녀석을 원자적으로 실행할 수 있을까? 하나의 명령어로 해결된다면 좋겠지만 일반적으로는 불가능하다. B-tree의 값을 원자적으로 갱신하는 어셈블리 명령어같은게 있을까? 그런 건 없다.
하드웨어 동기화 명령어와 운영체제의 지원을 통해 한 번에 하나의 쓰레드만 임계 영역에서 실행하도록 구성된, 제대로 잘 작동하는 멀티 쓰레드 프로그램을 작성할 수 있다.
5. 또 다른 문제: 상대 기다리기
지금까지는 병행성 문제를 공유 변수 접근에 관련된 쓰레드 간의 상호 작용 문제로 정의하였지만, 실제로는 하나의 쓰레드가 다른 쓰레드가 동작을 전부 끝낼 때까지 대기해야 하는 상황도 일어난다. 프로세스가 디스크 I/O를 요청하고 응답이 올 때까지 기다리는 경우 등이 있다.
6. 정리: 왜 운영체제에서?
왜 이런걸 운영체제에서 다루는걸까? 이것이 “역사” 이기 때문이다. 운영체제는 최초의 병행 프로그램이었고 운영체제 내에서 사용을 목적으로 다양한 기법들이 개발되었다. 나중에는 멀티 쓰레드 프로그램이 등장하면서 응용 프로그래머들도 이 문제를 고민하게 되었다.
시도 때도 없이 발생하는 인터럽트가 앞서 언급한 모든 문제들의 원인이다. 페이지 테이블, 프로세스 리스트, 파일 시스템 구조 그리고 대부분의 커널 자료 구조들이 올바르게 동작하기 위해서는 적절한 동기화 함수들을 사용해야 한다.